Key multipliers: Impact (\(\beta_0\)), delayed (\(\beta_s\)), and long-run (\(\sum_{s=0}^q \beta_s\))
ARDL model: Combines lagged dependent variable with distributed lags of explanatory variables
Critical assumption: Error term must be independent of all \(x\)’s (past, current, future) and serially uncorrelated
Application: Okun’s Law shows GDP growth reduces unemployment with distributed effects
Given the dynamic relationship of time series data, there are three different ways of modeling these relationships.
The dependent variable \(y\) is a function of current and past values of an explanatory variable \(x\). That is,
\[
y_t = f(x_t, x_{t-1}, x_{t-2}, \ldots)
\]
We can think of \((y_t, x_t)\) as denoting the values of \(y\) and \(x\) in the current period; \(x_{t-1}\) denotes the value of \(x\) in the previous period, \(x_{t-2}\) denotes the value of \(x\) two periods ago, and so on. Because of the lagged effects, the above equation is called a distributed lag (DL) model.
Specify a model with a lagged dependent variable as one of the explanatory variables.
\[
y_t = y(y_{t-1}, x_t)
\]
We can also combine the first two features of the above and previous equation so that we have a dynamic model with lagged values of both the dependent and independent variables, such as
Such models are called autoregressive distributed lag models (ARDL). As we have shown, the ARDL model is composed of an autoregressive component, which is the dependent variable regressed on one or more of its past values, and a distributed lag component, which is the independent variable and one or more of its lagged components.
A third way of modeling the continuing change over several periods is via an error term. For example, using \(f(\cdot)\) and \(g(\cdot)\), both of which are replaced later with linear functions, we can write
where the function \(e_t = g(e_{t-1})\) is used to denote the dependence of the error term on its value in the previous period. In this case, \(e_t\) is correlated with \(e_{t-1}\), and in such a scenario, we say the errors are serially correlated or autocorrelated.
Stationarity
An assumption that we will maintain throughout this exercise is that variables in our equation are stationary, which means that a variable is one that is not explosive, nor trending, and nor wandering aimlessly without returning to its mean. A stationary variable simply means a variable whose mean, variance and other statistical properties remain constant over time.
15.1 Finite Distributed Lags
The first dynamic relationship we consider is the first model that we introduced, which took the form of \[
y_t = f(x_t, x_{t-1}, x_{t-2}, \ldots),
\] with the additional assumption that the relationship is linear, and after \(q\) time periods, changes in \(x\) no longer have an impact on \(y\). Under these conditions, we have the multiple regression model:
The above model can be treated in the same way as a multiple regression model. Instead of having a number of different explanatory variables, we have a number of different lags of the same explanatory variable. This equation can be very useful in two ways:
Forecasting future values of \(y\).
To introduce notation for future values, suppose our sample period is \(t = 1, 2, \ldots, T\). We use \(t\) for the index and \(T\) for the sample size to emphasize the time series nature of the data. Given the last observation in our sample is at \(t = T\), the first post-sample observation that we wish to forecast is at \(t = T + 1\). The equation for this observation can be given by:
For example, to use an economic example, understanding the effects of the change in interest rate on unemployment and inflation, or the effect of advertising on sales on a firm’s products. The coefficient \(\beta_s\) gives the change in \(E(y_t)\) when \(x_{t-s}\) changes by one unit, but \(x\) is held constant in other periods. Alternatively, if we look forward rather than backward, \(\beta_s\) gives the changes in \(E(y_{t+s})\) when \(x_t\) changes by one unit, but \(x\) in other periods is held constant. In terms of derivatives:
The effect of a one-unit change in \(x_t\) is distributed over the current and next \(q\) periods. It is called a finite distributed lag model of order \(q\) because it is assumed that after a finite number of periods \(q\), changes in \(x\) no longer have an impact on \(y\).
To interpret the coefficients:
The coefficient \(\beta_0 = y_t - y_{t-1}\) is called the impact multiplier or impact propensity, which shows that the immediate change in \(y\) due to one-unit increase in \(x\) at time \(t.\)
The coefficient \(\beta_s\) is called a distributed-lag weight or an \(s\)-period delayed multiplier.
\(\beta_1 = y_{t+1} - y_{t-1}\) is the change in \(y\) one period after the temporary change in \(x\) at time \(t\); \(\beta_2 = y_{t+2} - y_{t-1}\) is the change in \(y\) two periods after the change; at time \(t+q+1,\)\(y\) has reverted back to its initial level: \(y_{t+q+1} = y_{t-1}\) because we have assumed that only \(q\) lags of \(x\) appear in (15.1).
Adding up a portion of the coefficients gives you the interim multipliers. For example, the interim multiplier for two periods would be \((\beta_0 + \beta_1 + \beta_2)\).
The long-run propensity (LRP), also called the long-run multiplier or total multiplier, is the final effect on \(y\) on the sustained increase after \(q\) or more periods have elapsed and is given by the equation:
\[
\text{LRP} = \sum_{s=0}^q \beta_s
\]
\(\mathrm{LRP}\) measures the the long-run change in \(y\) given a permanent increase in \(x\) at time \(t.\) For example, assume \(x\) equals a constant \(c\) before time \(t.\) At time \(t\), \(x\) increases permanently to \(c+1.\)
Mathematically,
\[
x_s = \begin{cases}
c & s<t \\
c+1 & x\ge t
\end{cases}
\] Two graphs that are related to the multipliers:
Lag distribution, which graphs the \(\beta_s\) as a function of \(s\), summarizing the dynamic effect that a temporary increase in \(x\) has on \(y\)
Cumulative effects as \(\beta_0 + \beta_1 + \cdots + \beta_h\) for any horizon \(h\)
15.2 Assumptions
In distributed lag models, both \(y\) and \(x\) are typically random. That is, we do not know their values prior to sampling. We do not “set” output growth, for example, and then observe the resulting level of unemployment. To accommodate for this stochastic process, we assume that the \(x\)’s are random and that the error term \(e_t\) is independent of all \(x\)’s in the sample – past, current, and future. This assumption, in conjunction with the other multiple regression assumptions, is sufficient for the least squares estimator to be unbiased and to be BLUE, conditional on the \(x\)’s in the sample.
\(y\) and \(x\) are stationary random variables, and \(e_t\) is independent of current, past, and future values of \(x\)
\(E(e_t) = 0\)
\(\var(e_t) = \sigma^2\)
\(\cov(e_t, e_s) = 0 \quad t \ne s\)
\(e_t \sim N(0, \sigma^2)\)
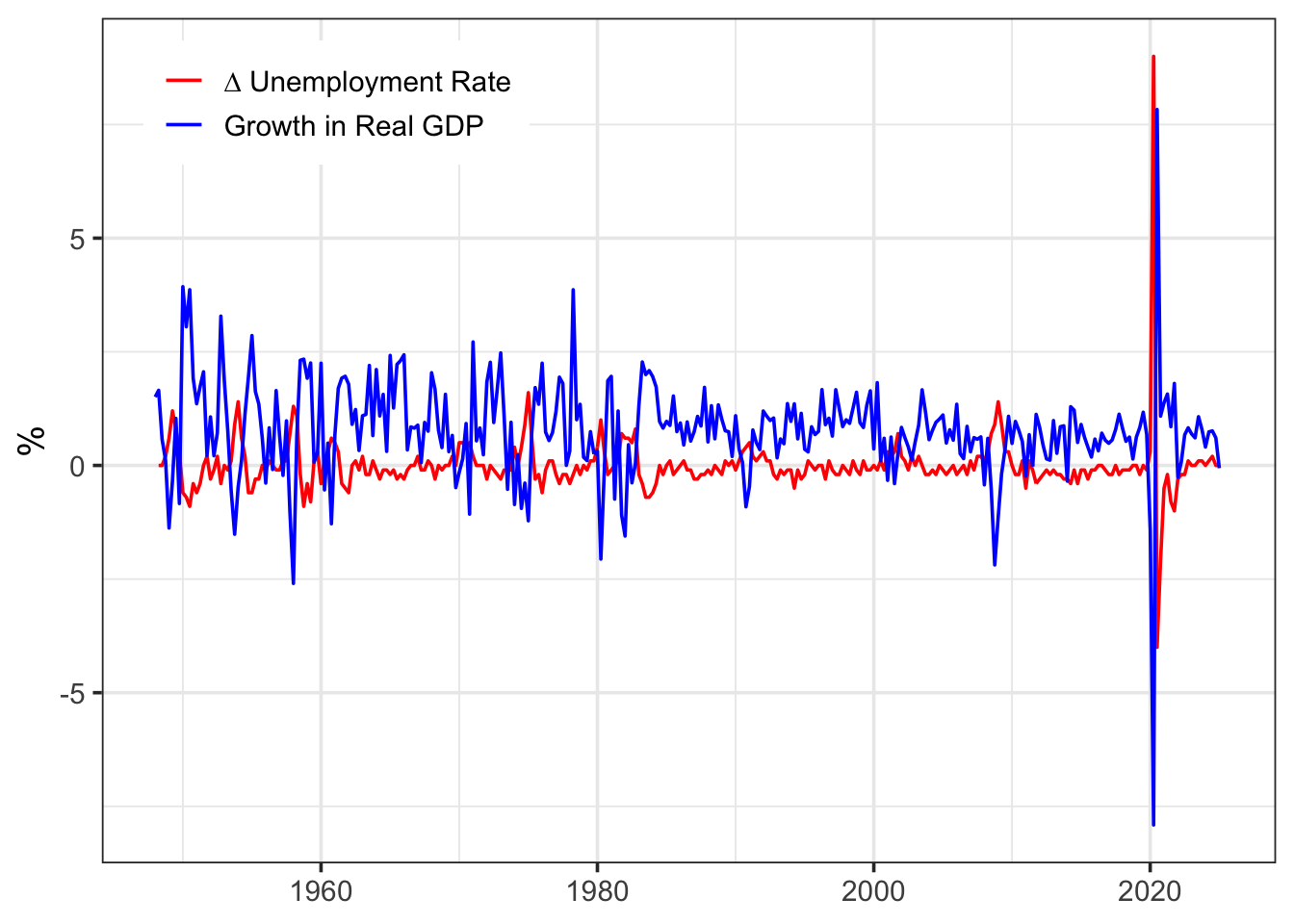
15.3 Application: Okun’s Law
We will apply the finite distributed lag model to Okun’s Law. Arther Melvin Okun was an economist who posited that higher output growth reduces unemployment. Mathematically, Okun’s Law can be expressed as
\[
U_{t}-U_{t-1}=-\gamma(G_{t}-G_{N})
\] where
\(U_{t}\) is the unemployment rate in period \(t\),
\(G_{t}\) is the growth rate of output in period \(t\), and
\(G_{N}\) is the “normal” growth rate, which we assume constant over time.
We can rewrite the above equation in more familiar notation of the multiple regression model by denoting the change in unemployment as
\[
DU_{t} = \Delta U_{t} = U_{t}-U_{t-1}.
\] We then set \(\gamma = \beta_{0}\) and \(G_{N} = \alpha.\) Including an error term to our equation yields
Acknowledging the changes in output are likely to have a distributed-lag effect on unemployment – not all of the effect will take place instantaneously. We can then further expand our equation to
f_name <-"https://raw.githubusercontent.com/my1396/course_dataset/refs/heads/main/okun.csv"okun2 <-read_csv(f_name)okun2 <- okun2 %>%mutate(dunemp =c(NA, diff(unemp)) )# convert data to a time series objectokun2.zoo <- okun2 %>%xts(x = .[,-1], order.by =as.yearqtr(.[[1]])) %>%as.zoo()okun2
A 1 percentage point increase in the growth rate of GDP leads to a fall in the change of unemployment rate by 0.44 percentage points in the current quarter, a fall of 0.09 percentage points in the next quarter. The delayed effects stop beyond the first lag.
which is an autoregressive distributed lag model (ARDL(1,1)). It is called an autoregressive distributed lag model because the dependent variable is regressed on its lagged value (the autoregressive component), and it also includes explanatory variables and their lagged values (the distributed lag component).
ARDL(\(p, q\)) is a model with
\(p\) lags of the dependent variable (AR(\(p\))) and
\(q\) lags of the independent variable (DL(\(q\))).
This equation can be estimated by linear least squares providing that the \(v_t\) satisfy the usual assumptions required for least squares estimation, namely that they have zero mean and constant variance, and are not autocorrelated.
The presence of the lagged dependent variable \(y_{t−1}\) means that a large sample is required for the desirable properties of the least squares estimator to hold, but the least squares procedure is still valid providing that \(v_t\) is uncorrelated with current and past values of the right-hand side variables.
It is crucial that \(v_t\) be serial uncorrelated. If they are serial correlated, e.g., \(v_t=u_t-\rho u_t\), the least square estimator will be biased, even in large sample sizes!
Models ARDL(1,1), ARDL(1,0) (autoregressive model), and ARDL(0,1) (distributed lag model) are of special interest to users because they provide information about the short-run and the long-run relationship between two variables \(z_t\) and \(y_t,\) assuming that variables \(z_t\) is strictly exogenous, i.e., \(z_t\) is uncorrelated with \(v_t\) and \(y_{t-1}\).
ARDL(1,1) and ARDL(1,0) allow estimation of both short-run and long-run effects
ARDL(0,1) does not allow this, because there’s no lagged \(y_t\) — no dynamic accumulation
This helps answer:
Are the effects of changes in \(z_t\) temporary or permanent?
Persistence in the Dependent Variable
This refers to how much the past value of \(y_t\) influences its current value.
When \(y_{t-1}\) is included, it means that the current value of \(y_t\) is influenced by its past value, which implies that shocks to \(y_t\) will have a persistent effect over time.
In absence of \(y_{t-1}\), the model focuses on the immediate relationship between \(z_t\) and \(y_t\) without considering past values of \(y_t\).
15.4.4 Example: temperature changes affecting GDP
Let:
\(y_t\): GDP growth rate at time \(t\)
\(z_t\): temperature anomaly (e.g., deviation from normal)
We want to understand how temperature shocks (e.g., a heatwave or cold year) affect economic performance — both now and in the future.
Last year’s GDP growth (\(y_{t-1}\)) — persistence
This year’s temperature (\(z_t\)) — immediate effect
Last year’s temperature (\(z_{t-1}\)) — delayed effect
Real-World Example:
A hot year reduces agricultural output this year (immediate effect), and possibly reduces capital investment or damages infrastructure, which lowers next year’s growth too (delayed effect).
Meanwhile, GDP tends to persist over time due to investment cycles and habits.
The ARDL model (15.4) assumes the effects of growth in output persists, while FDL(\(q=1\)) model (15.3) assumes the change in employment responds to changes in output growth only over two periods (current and the last periods).
A 1% increase in the change of unemployment rate from the previous quarter leads to a 0.056% decrease in the change of unemployment rate in the current quarter. This suggests a mild mean-reverting behavior: unemployment shocks tend to partially reverse in the following quarter, but the effect is small and statistically insignificant.
A 1% increase in the growth rate of GDP leads to a fall in the change of unemployment rate of 0.43% in the current quarter, a fall of 0.12% in the next quarter.
References
Czar Yobero, Time Series Regression with Stationary Variables: An Introduction to the ARDL Model, https://rpubs.com/cyobero/ardl